There have been some notable/significant developments in machine learning lately. The pace of progress continues to be impressive, and it’s exciting to see how quickly the field is evolving. The great progress in large language models (LLMs)/vision language models (VLMs) is making a lot of problems possible to tackle and a lot of companies are now building their businesses around wrappers of such models.
One of the most appealing characteristics of such models is machine learning processing coming out-of-the-box – no data annotation or costly, time-consuming training is needed. You get value from the moment you deploy the solution.
Out-of-the-box models are possible and existed before the appearance of LLMs and VLMs, but there are two main reasons why out-of-the-box approach is particularly interesting for these models:
- LLMs and VLMs are pre-trained on huge amounts of data, which gives them a lot of context and so it is more feasible to use them out-of-the-box for a wide range of tasks
- Training an LLM or VLM(from scratch) is very expensive, requires infrastructure that most companies would not have, and also takes a lot of time.
An out-of-the-box solution is helpful in many cases but it comes with inherent challenges and risks. In this article, we will focus on highlighting some of those challenges and discuss what can be done to mitigate them.
Out-of-the-box models can be used to solve many tasks but given our focus on automating document processing I will be mostly using examples from this area.
Different Business Rules
The same task, provided the same input, may be performed differently in two different companies, even if they are in the same industry.
For example,Company A and Company B may have a different way to extract information from invoices. Let’s consider extracting the “ship to address” from the invoice below that does not have it listed explicitly.
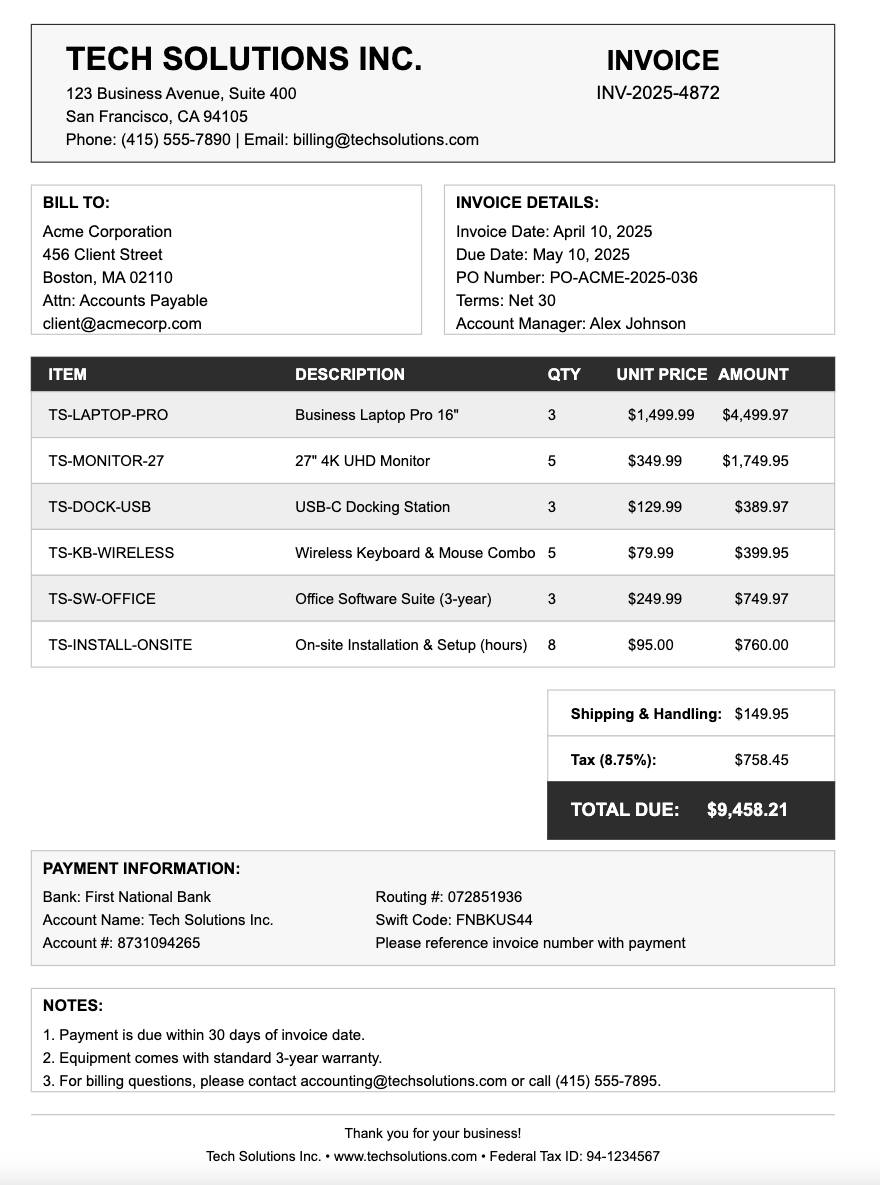
In company A, this case may be handled by saying that the field is not present, while in company B, they use the value of the “bill to address” instead. It is not possible for an out-of-the-box model to behave in both ways, without providing it context. Given the same input without additional information, it is supposed to produce the same output. Thus it is unlikely that the model “just works” without the consumer having to do anything.
In this situation, the two companies – A and B – have different business rules on how the same task should be performed and we need to find a way to provide these rules as context to the model. In general there are two ways to achieve this:
- Program these rules explicitly – this could be via coding logic or for instance as part of the prompt (in the case of LLMs/VLMs)
- Show examples of expected extraction to the model and “train” it on them
Both approaches would work, but in our experience organizations often don’t have systemized rules or the set of rules is very big and providing them explicitly would either be a lot of work or not feasible at all. On the other hand, usually customers have a lot of data they’ve already processed and it is much easier to provide (part of) this data to derive business rules from. The challenge then becomes ensuring that the data is diverse enough (it includes all relevant business rules with enough representation) and it is accurate enough. Practically any set of data will have some errors and each error may negatively affect the end performance of the system. Thus a good machine learning system should allow for review, correction and versioning of data.
Data Poisoning
The data that a model was trained on determines the predictions it makes. This data should be carefully curated by a trusted party or else it could present a security concern. By altering the training data, a malicious party may control predictions that the model will make in the future.
Here I will use a somewhat simplified example that I hope will demonstrate the problem. Let’s imagine a malicious AI company called SneakyAIThieves that is implementing an out-of-the-box model for payment checks extraction. They train their model on a lot of data and it is a perfectly valid model that performs very well. However, when creating the training data, for all checks where the payee name is SneakyAIThieves, they multiply the expected extracted amount by 10 (and they also make sure there are enough of those in the training data). Their model will pick up this dependency and then make similar 10 times higher predictions any time it sees SneakyAIThieves as payee. SneakyAIThieves make their model available as an out-of-the-box model and as it is really good some companies start using it for automatically extracting data from payment checks. Now SneakyAIThieves can utilize the backdoor they’ve backed into the model and when they get this check:

They would actually receive 1000 dollars.
Altering the data so that you affect the model predictions is called “data poisoning”. It is very hard to detect it only based on the out-of-the-box model and thus it is very important that you trust the party that produced it. Even after fine-tuning a model that is tampered with in this manner will likely continue to be “poisoned”.
Sometimes data poisoning is not a deliberate action by the one training the model. Many models and in particular LLMs and VLMs are trained on enormous amounts of data. A lot of data on the internet is user generated, so during data collection we should pay attention that we don’t inadvertently introduce poisoning.
Imagine a public figure (let’s name him John Smith). Over the last couple of years the label autistic was used as a slur in some internet communities. If a big enough community labels John Smith as autistic, the model could memorize that. If there’s a process that extracts from medical reports autism as a medical diagnosis and we pass a medical report for John Smith, we could see a false positive of John Smith’s autism. This could happen, because the model was pretrained with that knowledge. Similar things happen sometimes with machine translation solutions and user reviews based recommendation systems – every now and then a group of users that provide incorrect information may lead to incorrect predictions.
Bias
Bias is a tendency to lean in a certain direction—often unfairly—based on personal preferences, assumptions, or external influences. As everyone perceives the world around them differently, pretty much everyone will have some biases, most of them “innocent”. Additionally, oftentimes people that share certain traits share biases. For instance people living in the same region/country, people of similar age or people of similar occupation have some common biases. The data generated by such groups would be biased, too.
Another point is that because of the way data on the internet is generated, it does not necessarily represent the viewpoints of everyone. For instance poor people are much less likely to have internet access (and thus generate internet content).
Without taking special care machine learning models trained on biased data tend to show the same biases or even amplify them. This often combines with the fact that LLMs/VLMs sometimes show the tendency to be overconfident which leads to undesirable outcomes. As an example take this loan application:

It does not explicitly indicate the gender of the applicant, however it is a field that the system may attempt to extract. There is an imbalance in the US for both gender compensation and how many male vs female employees there are in technology, so based on the high salary and position in technology, the model may decide it is more probable that the person’s gender is Male. As indicated previously, many LLMs/VLMs show a tendency to be overconfident – they would rarely say “I don’t know” and so the model will “hallucinate” the value which of course is undesirable.
A counter example is this medical report:

Let’s assume that in this example again the system wants to extract the person’s gender. The field is not explicitly listed, however the diagnosis is High-Risk pregnancy, thus one would expect from the model to be able to identify the gender as “female”.
It is important to note that if a model is pre-trained on biased data, fine tuning may not be enough to eliminate the bias.
We use and recommend using LLM/VLMs where specific steps have been added to their training process to eliminate/reduce their overconfidence.
Conclusion
In conclusion it is important to note that there is not a single silver bullet solution capable of solving all tasks. A good system should provide a set of tools and the right implementation should use the right tool for the right tasks. Out-of-the-box models are an important tool to solving real world problems. However, like any tool they come with certain limitations and downsides.
At Hyperscience we’ve developed a powerful and flexible solution that allows for different approaches to incorporating business context and control of the model predictions:
- Custom code blocks provide the ability to apply custom logic on the extracted data
- The prompt (in VLM/LLM case) can be customized when defining what fields are to be extracted
- We provide the option to fine-tune the model. As mentioned before, re-training the whole model is not feasible due to resource constraints, but it is possible to fine tune its behavior based on a small set of examples.
In combination with Hyperscience’s orchestration, accuracy harness and other key features, we address a wide range of tasks related to document extraction, understanding and processing.